If you are a .NET developer trying to apply Domain Driven Design (DDD) or working with ASP.NET MVC, most likely you would be required to implement a repository that handles object persistence and retrieval. Several Object Relations Mapper (OR/M) are available for .NET and given tight integration of Entity Framework with ASP.NET MVC, MvcScaffolding and in general with .NET framework, Entity Framework could be a valuable option.
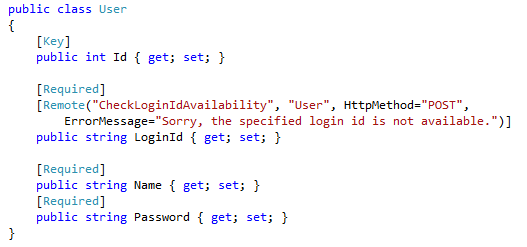
Well, if you have decided to use Entity Framework to construct your repository, your next design consideration could be how to keep it simple while separating the responsibility clearly. Entity Framework nicely abstracts interaction with database providing rich features such as identity map, lazy loading etc. Implementing a repository using EF is fairly a simple task, yes - you don't need to write lot of code looking to convert database specifics to object specifics, instead just derive your class from DbContext and your repository is ready. Look at the following example for the simplest implementation of a repository using EF.
public class Repository : DbContext
{
public DbSet<Customer> Customers { get;
set; }
public DbSet<Order> Orders { get;
set; }
}
Yes, that's as simple as that. The above class is more than enough to return/persist Customers and Orders from/to database. It is pretty simple and straight forward, but does it pose any problem? Yes, it has some issues that could be potential at times.
Does it really returns Customers and Orders? Does it really return collections which you can query on your own? No, not really. It returns DbSet<TEntity> which is IQueryable<T>.
The IQueryable<T>
Is IQueryable<T> a collection? Well, no, it is really an expression which will be interpreted by the underlying provider and converted into relevant SQL queries. Returning an IQueryable could be a disaster as you really don't have a 'real' repository which returns objects/aggregates instead you are returning IQueryable. So where is your repository now? Well, it could be spread over across other layers such as the controllers, services etc. More than that your developer(s) may write code similar to the one below.
var repository = new Repository();
var customers = repository.Customers.ToList()
.Where(k => k.Country == "US");
In the above code, the ToList() call will retrieve all the customers from the database into your physical memory and depending on the volume and requests, your system could suffer with significant performance issues.
In summary, returning IQueryable<T> from your repository can have impacts like mentioned above. However, if you have a disciplined development team or the system is relatively smaller, easier to manage, the above approach could be suffice and cost effective.
The big fat Repositories...
While the previous approach was quite simpler, you will find several materials recommending following the below design.

Though not shown explicitly, the repositories in this design return the entities or IEnumerable<T> and not IQuerable<T>. That is the repository always returns true objects and not IQueryable<T> which is an expression storing SQL - so it solves the IQueryable<T> problem. While it has well defined contract and responsibilities, on the other hand it is quite complicated. In this example, you just got two types of domain entities and have bunch of interfaces and classes already handling persistence/retrieval problem. When you are adding more domain entities you are like to see interface and class explosion. However in major complex systems this design will make it easier to maintain and support. But do you need to complicate your design early in your development? Or does your system really requires this level of detailed interface segregation? Especially does the complexity of domain problem you are trying to solve warrant this kind of complexity?
Another approach...
An alternate implementation as below balances the complexity above.
public class DataContext : DbContext
{
protected DbSet<Customer> Customers { get;
set; }
protected DbSet<Order> Orders { get;
set; }
}
public class Repository : DataContext
{
public void
Add<T>(T entity) where T : DomainEntity
{
base.Set<T>().Add(entity);
}
public void
Delete<T>(T entity) where T : DomainEntity
{
base.Set<T>().Remove(entity);
}
public IEnumerable<T>
GetEntities<T>(Expression<Func<T, bool>> predicate) where
T : DomainEntity
{
return base.Set<T>().Where(predicate).ToList();
}
public T GetById<T>(int
id) where T:DomainEntity
{
return base.Set<T>().FirstOrDefault<T>(k
=> k.Id == id);
}
}
The above implementation applies generics and keep the implementation simple without too many interfaces and classes while resolving the issues relating to exposing IQueryable<T>. There could be multiple variations of the above implementation better suiting your needs, however the intention is to demonstrate various available alternate designs. And I'm not saying that this is a solution fitting all the scenarios.
So, which of the above approach should be applied to your problem? It depends... You have to consider multiple factors, the primary one being the domain object model - how complex it is? Are your development team is disciplined and ready to refactor any time? Are the developers in your team understand details of OR/M especially the lazy loading, IQueryable<T> etc. In any case, do not over engineer when starting with - start with the simpler approach and continuously improve the implementation.